Remember 2020 when the world shut down to slow the spread of Covid and we had to figure out what to do while we waited patiently in our homes for the end of times? During breaks from Daddy daycare and an endless loop of Moana playing on our TV I developed a simple pipeline for on-device image retreaval. It’s fast, compact, and memory efficient. In this article I will share the story of how I developed Board Game Snapshot (BG Snapshot), an iOS App that utilizes the camera to identify board games. Along the way I will provide you with the motivation for working in embedded spaces, talk in brief about contrastive learning methods, give a whorl wind tour of approximate nearest neighbors search, and introduce SwiftAnnoy, an open-source wrapper library that you can use in your own applications.
The genesis of my app idea
For more than a decade a group of some of my closest friends and I have gathered for an extended weekend of non-stop board gaming we call Nerdfest. The games we play don’t have household names like Monopoly, Battleship, or Risk. Some of our favorites have names like Terraforming Mars, Peurto Rico, and Root. The games are often complex, richly themed, and lengthy (sometimes > 3 hrs). For those not familiar with the hobby, you can check out Board Game Geek (BGG). BGG is the Wikipedia for all things board game related and includes pages for tens of thousands of games! In fact the sheer volume of choices was one source of inspiration for BG Snapshot. The other came from my local game store. I found myself constantly using BGG to get ratings and reviews of games that looked interesting as I perused the shelves, but was annoyed by all the typing I had to do. My solution, as you may have guessed from the name BG Snapshot, was to develop a machine learning pipeline that utilizes the camera to detect and identify board games, ditching the keyboard altogether.
On 1 of K classifiers
With an app idea in mind I began to think about what sort of machine learning model might work best for board game recognition. My first thought was to train up a traditional convolutional neural network (CNN) that uses a linear layer with softmax activation for classification. It would have been a fitting choice for 2020. There were and still are a lot of papers being published trying to squeeze out accuracy on datasets like Imagenet (see image below).
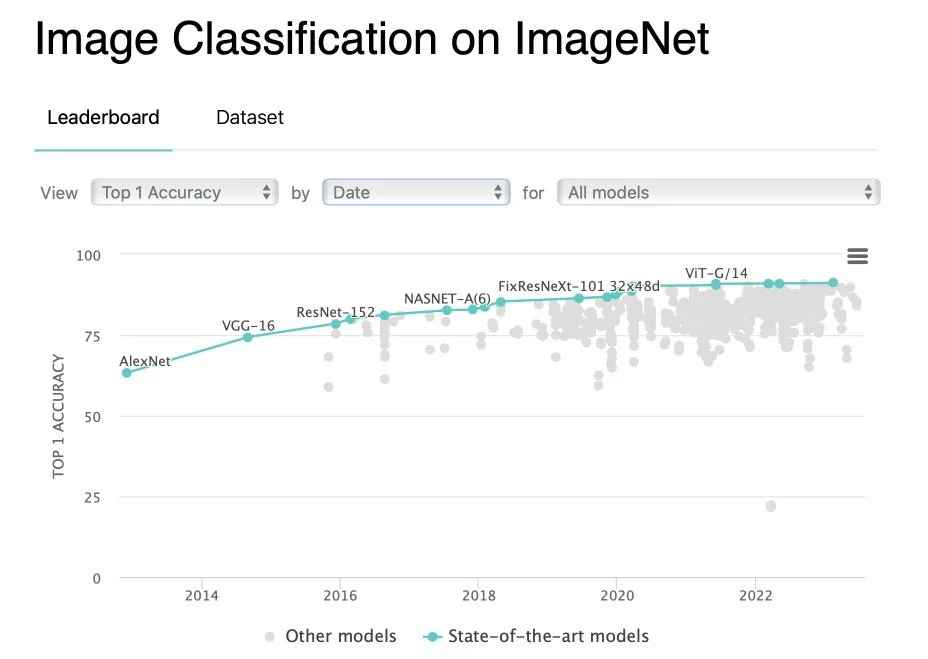
Source: paperswithcode accessed 7/5/2023
But there are a number problems with this approach.
The last layer of the network, which is linear, can quickly end up gobbling up a ton of memory if you aren’t careful. BGG, which has more than 100K games would require hundreds of MB for the classification layer alone. Not a suitable option for mobile!
Whenever you want to add an additional class you have to retrain the entire network from scratch…and since new board games come out every day this poses a significant problem
The softmax function becomes computationally expensive with a large number of classes. (longer/more challenging training)
Deep learning models need lots of examples for each class…with board games it was apparent finding a large pool of images to draw from would be a challenge.
The bottom line is this:
One of k classifiers work best when you have a fixed number of classes, when k is relatively small, and when you have plenty of examples for each class.
For my board gaming problem I needed a different apprach. I needed a system that could adapt to new board games (classes) being added, could learn from a single example, and wouldn’t require constant retraining.
Embedding spaces and contrastive learning
The solution, as it turned out, was to use a combination of contrastive learning, image embeddings, and approximate nearest neighbors search. But before I get ahead of myself, let me first give a brief introduction to embedded spaces and contrastive learning.
An embedded space, also known as latent space, provides a low dimensional landscape for describing high dimensional data. In practice, a typical embedded space has anywhere from a few hundred to a few thousand dimensions, a significant decrease from the millions of dimensions for raw text and image data. Data that are projected into this embedded space, which we now call a vector embedding, provide two important advantages over raw data.
The reduction in size and memory footprint make trainig ML models, especially larger ones, tractable
Embeddings carry both spatial and semantic information
The relationships between embeddings can be visualized using t-SNE, a method that further reduces a dataset to just two or three dimensions. Take a look at this plot of vector embeddings that arise naturally from a pre-trained ResNet101 classification model on the Animals10 dataset below.
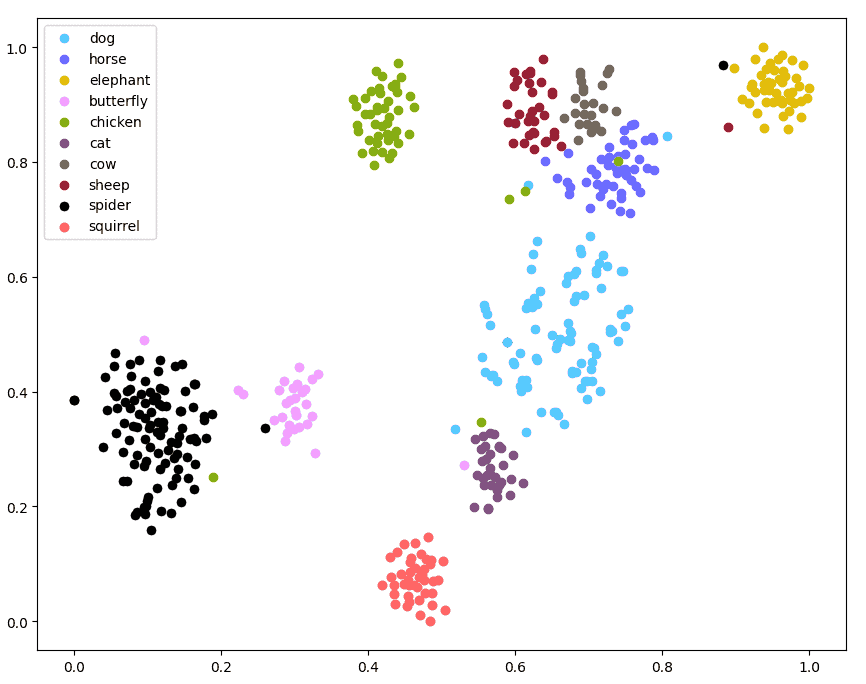
https://learnopencv.com/t-sne-for-feature-visualization/
Here we can see some pretty nice clusters for each type of animal. As a bit of foreshadowing, if we precomputed all of the vectors from Animals10 and stored them, we could use a nearest neighbors search to classify the vector embedding for a new image of a dog taken from my cellphone. This may work well for classes this model has previously seen, but will likely struggle with out of domain data or if say, I wanted the model to give back the breed of dog in my image not just the fact that it’s a dog. For something like that we need a more robust training method better suited to the task, which brings us to contrastive learning.
Contrastive learning is a form of self-supervised learning that aims to pull similar training examples closer together while pushing dissimilar examples farther apart. For BG Snapshot I decided to use the triplet loss, first introduced in Google Brain’s FaceNet paper. [1]
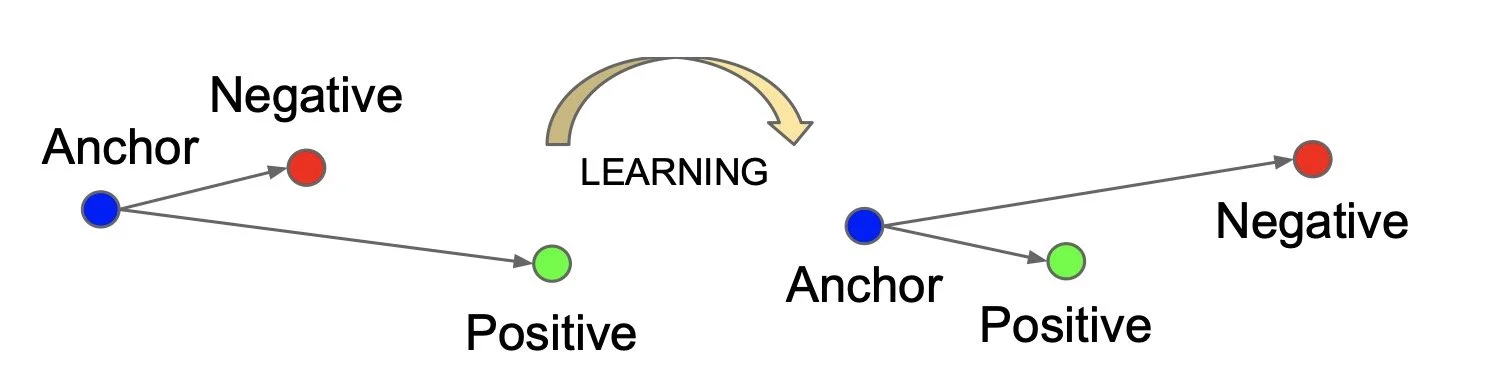
Visualization of triplets before and after learning. Source: FaceNet Paper
Here, a triplet is formed by selecting one example image as the anchor, a second from the same class as a positive example, and a third from a different class as a negative example. The formal definition for the loss from the paper is:

Source: FaceNet
In essence, minimizing this loss decreases the distance between the anchor and positive examples while pushing negative examples farther away from anchors with a margin 𝛼.
In BG Snapshot I used the original game images as anchors, augmented images (with blur, rotation, etc.) as positive examples, and the remaining images in a given batch as negative candidates.

Sample triplet of board game images used to train BG Snapshot. Source: Author
I used MobileNetV2 for the CNN architecture as it has a relatively small number of parameters (3.5M), but still gives good performance in terms of inference speed and accuracy. Fine-tuning the model took longer than I would like to admit, but that’s often what it takes to get a model from the experimental phase to production ready.
And while triplet loss training worked for my project, it does come with its own set of challenges. One challenge is finding the ‘hard’ triplets to ensure your model converges quickly. Though there has been ample work in ‘online’ and ‘offline’ mining strategies, I stumbled into another challenge. There is an upper limit on model improvement imposed by the triplet loss. Said simply, after some time, most of the triplets in a given batch will no longer contribute to the loss function, even when selecting for the hardest triplets in an online fashion. For a more in-depth discussion on triplet loss, take a look at this post from Yusuf Sarıgöz to learn more.
If, after reading this article, you are thinking about starting your own project I would recommend trying more contemporary methods like SimCLR [2], Barlow Twins [3], or BOYL [4]. These methods forgo explicitly pushing images of differing classes apart and instead focus on pulling similar images together using image augmentation to generate multiple views of each instance.
Approximate Nearest Neighbors
Once I had embeddings with sufficiently small intraclass distances and sufficiently large interclass distances (see image below), I built a crude prototype in iOS to see if I could get my image retrieval system working. To do that I saved the embeddings of 5000 board games, some of which I own, to act as a dictionary for testing. Then I used a simple brute force nearest neighbors search as a lookup mechanism. As a reminder, a stored embedding of a game in our dictionary should be the closest item to a new embedding of that same game captured with the camera, relative to all of the other games in our dictionary.
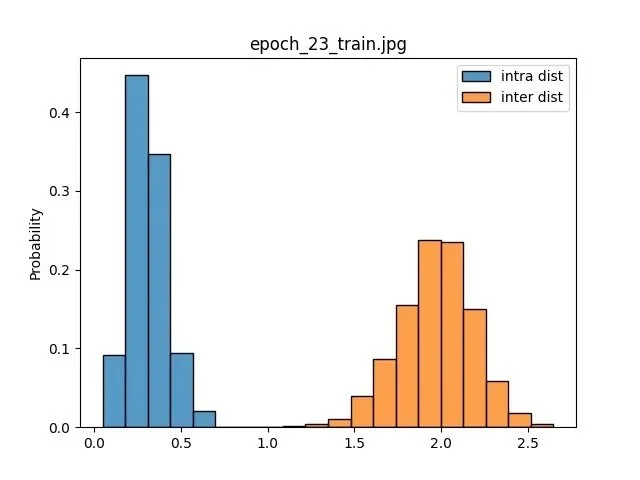
Histogram showing the separation of intraclass and interclass distributuions. Source: Author
This ‘dictionary’ storage approach is what gives the instance retrieval system it’s flexibility. Adding new board games doesn’t require retraining the model. All we have to do is run inference on any new images we get and add them to our dictionary.
In case I forgot to mention, the distance metric being used in BG Snapshot is Euclidean distance, though cosine similarity is much more popular theses days and tends to work somewhat better in high dimensional spaces.
My prototype worked fairly well right out of the gate and got me really excited, but benchmarking and memory profiling showed a few shortcomings in my original implementation that would make scaling a challenge:
Nearest neighbors using brute force search has a time complexity that scales linearly O(N). Linear scaling isn’t bad (better than polynomial), but for a snappy app I needed a faster lookup mechanism that could scale to hundreds of thousands of examples without slowing down.
The demo app stored the entirety of the dictionary in memory. Though it made lookup faster I really wanted a model with a small memory footprint in the mobile environment.
This is where approximate nearest neighbor (ANN) algorithms come into play. ANN algorithms make a tradeoff. A small amount of accuracy is sacrificed for fast and efficient search speed. The library I ended up selecting is called Approximate Nearest Neighbors Oh Yeah (Annoy), which was developed at Spotify to assist with their music recommendation system.
Why Annoy? Three main reasons:
The search time for queries is O(logN). In practice just a few microseconds when I timed it with my Mac.
Annoy allows you to use memory mapping on your search index (dictionary)…meaning the index does not need to be loaded into RAM.
The Annoy library is a single 45 KB C++ file, making it extremely portable and easy to incorporate into a wrapped Swift libarary.
How does it work? Annoy makes a forest of binary trees that act as an index during lookup. When building the index, splits at each node in a tree are chosen by forming an equidistant hyperplane between two random datapoints. Points falling on each side of the hyperplane are used in subsequent rounds of random splitting until the leaves of the tree have at most k data points. During search, a query vector travels down the nodes in each tree based on its relationship to the hyperplanes defined during tree construction. After a limited number of nodes are searched, the algorithm gathers the datapoints left in leaf nodes from each tree and performs a mini brute force nearest neighbors search.
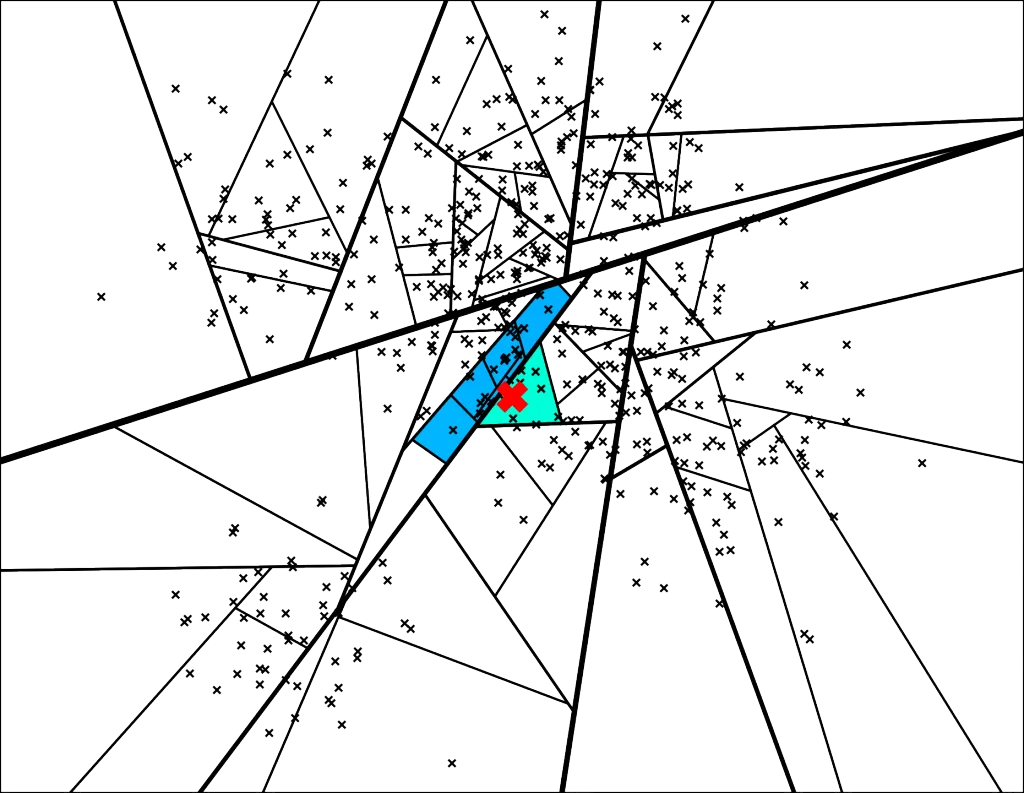
Example dataset showing a query vector (red x) and traversal down a tree built with Annoy. Source: https://erikbern.com/2015/10/01/nearest-neighbors-and-vector-models-part-2-how-to-search-in-high-dimensional-spaces.html
For a more detailed explanation and additional visualizations see this blogpost from Erik Bernhardsson, the author of Annoy.
Swift Annoy
To make Annoy work in iOS I wrote SwiftAnnoy. It’s a small wrapper package you can use in your own projects. The API is small, so allow me to give you a quick tour.
Create an index
First, you create an AnnoyIndex<T> as in:
let index = AnnoyIndex<Double>(itemLength: 2, metric: .euclidean)
Currently supported types are Float and Double. Distance metrics that you can use include angular (cosine similarity), dot product (inner product), Euclidean (L2 distance), and Manhattan (L1 distance).
Adding items
Next, add some data to your index. There are two functions that can be used to populate an index: addItem and addItems.
var item0 = [1.0, 1.0]
var item1 = [3.0, 4.0]
var item2 = [6.0, 8.0]
var items = [item0, item1, item2]
// add one item
try? index.addItem(index: 0, vector: &item0)
// add multple items
try? index.addItems(items: &items)
Note: Annoy expects indices in chronological order from 0…n-1. If you need/intend to use some other id numbering system create your own mapping as memory will be allocated for max(id)+1 items.
Build the index
In order to run queries on an AnnoyIndex the index must first be built.
try? index.build(numTrees:1)The parameter numTrees specifies the number of trees you want Annoy to use to construct the index. The more trees you include in the index the more accurate the search results will be, but it will take longer to build, take up more space, and require more time to search. Experiment with this parameter to optimize the tradeoffs.
Running queries
An AnnoyIndex can be queried using either an item index or a vector.
// by item
let results = index.getNNsForItem(item: 3, neighbors: 3)
print(results)
"Optional((indices: [3, 2, 0], distances: [0.0, 5.0, 8.602325267042627]))"
// by vector
var vector = [3.0, 4.0]
let results2 = index.getNNsForVector(vector: &vector, neighbors: 3)
print(results2)
"Optional((indices: [2, 0, 1], distances: [0.0, 3.605551275463989, 3.605551275463989]))"Saving an index
To save an index simply pass a URL as in:
let fileURL = FileManager.default.temporaryDirectory.appending(path: "index.annoy")
try? index.save(url: fileURL)Loading an indexLoading an index
To load a previously saved index use:
let index = AnnoyIndex<Double>(itemLength: 2, metric: .euclidean)
let fileURL = FileManager.default.temporaryDirectory.appending(path: "index.annoy")
try? index.load(url: fileURL)The final pipeline and closing thoughts
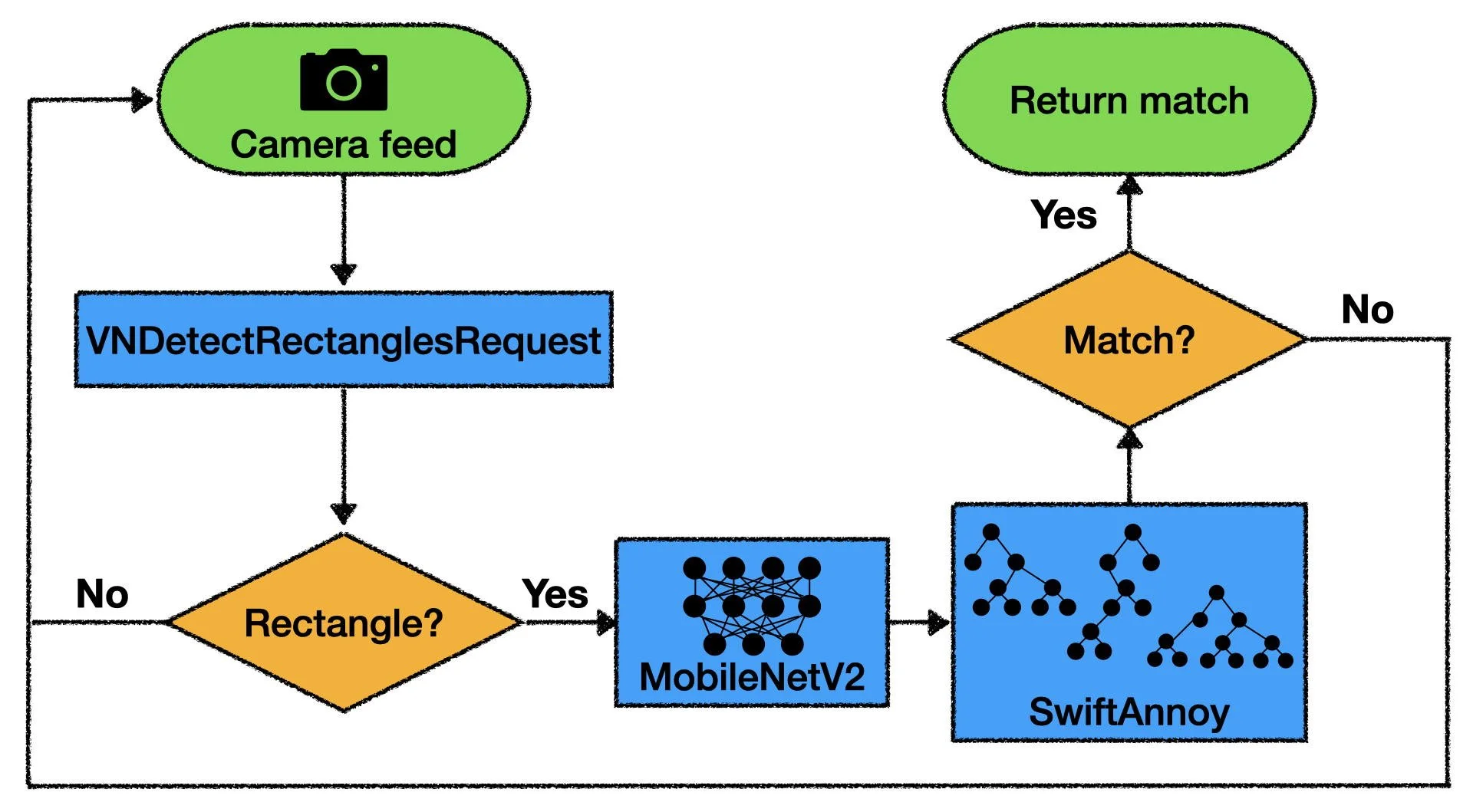
There is a bit more to the BG Snapshot developer story, but this article is getting rather long, so let’s wrap things up by taking a look at the complete instance retrieval pipeline.
Diagram of instance retrieval pipeline used in BG Snapshot. Source: Author
The first thing you will notice is that images from the camera feed aren’t pushed directly to MobileNetV2. There is a rectangle detection step in between. It turns out that most board games are rectangle shaped and isolating the ‘box’ component results in images that more closely match images used during triplet training. If you want to learn about how to do rectangle detection using Apple’s Vision framework I wrote a detailed article that you may find helpful.
Another aspect of the pipeline that I didn’t cover was how to determine when you actually have a match. What kind of accuracy and recall does the model give? To be a bit hand-wavy, I used multiple image captures and some heuristics to get the performance I was looking for.
I am really pleased with the final product. The entire machine learning payload (mlmodel, annoy index, and mapping file) takes up less than 40MB of space and a single round of inference only takes 25-30ms on my iPhone 12 Pro.
Thanks so much for reading!
References
F. Schroff, D. Kalenichenko, J. Philbin, FaceNet: A Unified Embedding for Face Recognition and Clustering (2015), Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2015
T. Chen, S. Kornblith, M. Norouzi, G. Hinton, Simple Framework for Contrastive Learning of Visual Representations (2020), ICML 2020
J. Zbontar, L. Jing, I. Misra, Y. LeCun, S. Deny, Barlow Twins: Self-Supervised Learning via Redundancy Reduction (2021), ICML 2021
J. Grill et. al., Bootstrap Your Own Latent
A New Approach to Self-Supervised Learning (2020), NIPS 2020